
告警规则Alert Rules
警报规则 rules 使用的是 yaml 格式进行定义,使用 PromQL 配置实际警报触发条件,Prometheus 会根据设置的警告规则 Ruels 以及配置间隔时间进行周期性计算,当满足触发条件规则会发送警报通知。
警报规则加载的是在 prometheus.yml 文件中进行配置,默认的警报规则进行周期运行计算的时间是1分钟,可以使用 global 中的 evaluation_interval 来决定时间间隔。
语法都一样,除了 recording rules 中的收集的指标名称 record: <string> 字段配置方式略有不同,其他都是一样的。
修改、添加配置规则:
vim prometheus-server-rules.yml
...
alert-rule-node.yaml: |
groups:
- name: operations
rules:
- alert: node-down
expr: up{job="kubernetes-nodes"} != 1
for: 5m
labels:
level: Critical
team: operations
annotations:
description: "Environment: {{ $labels.env }} Instance: {{ $labels.instance }} is Down ! ! !"
value: '{{ $value }}'
summary: "The host node was down 5 minutes ago"
- alert: node-memory-usage
expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes)))* 100 > 90
for: 1m
labels:
level: Warning
team: operations
annotations:
description: "Environment: {{ $labels.env }} Instance: {{ $labels.instance }} memory usage above {{ $value }} ! ! !"
summary: "node os memory usage status"
kubectl replace -f prometheus-server-rules.yml curl -X POST http://172.16.220.143:30090/-/reload

以第一个规则为例,Prometheus 在周期检测中使用PromQL以job=”kubernetes-nodes”为维度查询,如果当前查询结果中具有标签job=”kubernetes-nodes”,且返回值都不等于1的时候,发送警报。
可以在图形界面中检查判断语句运行:
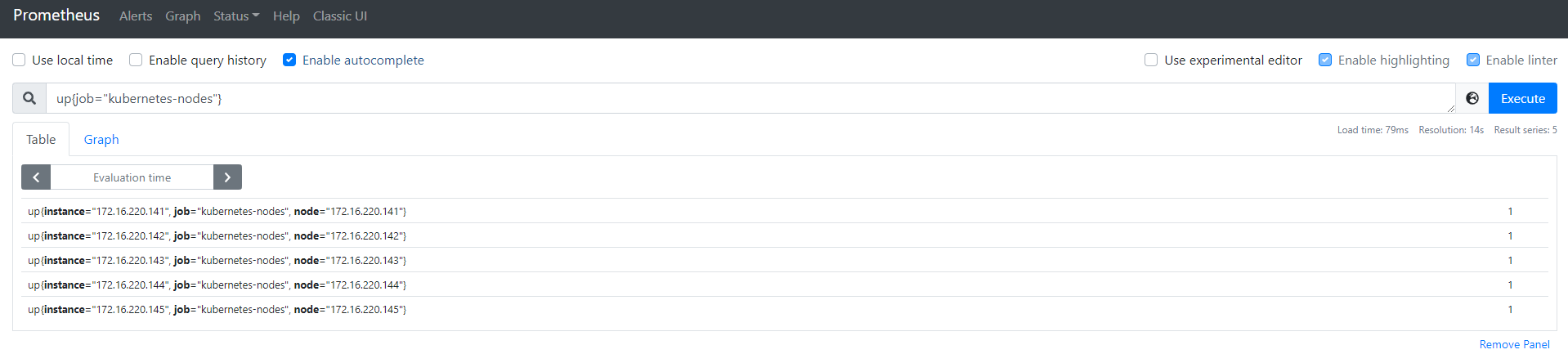
点击Alters查看当前告警规则:
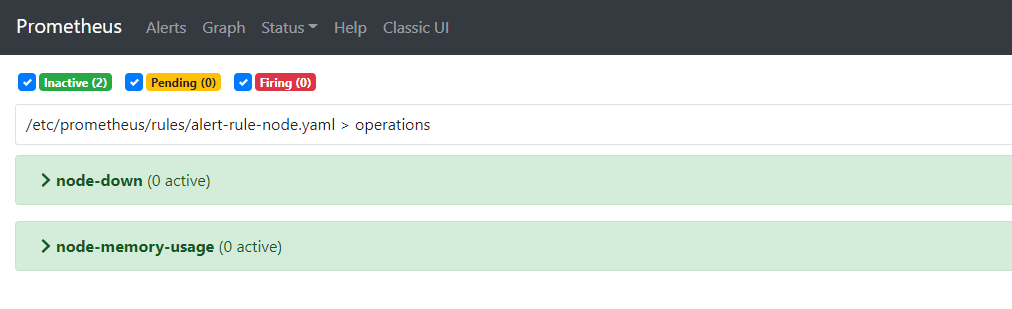
触发告警
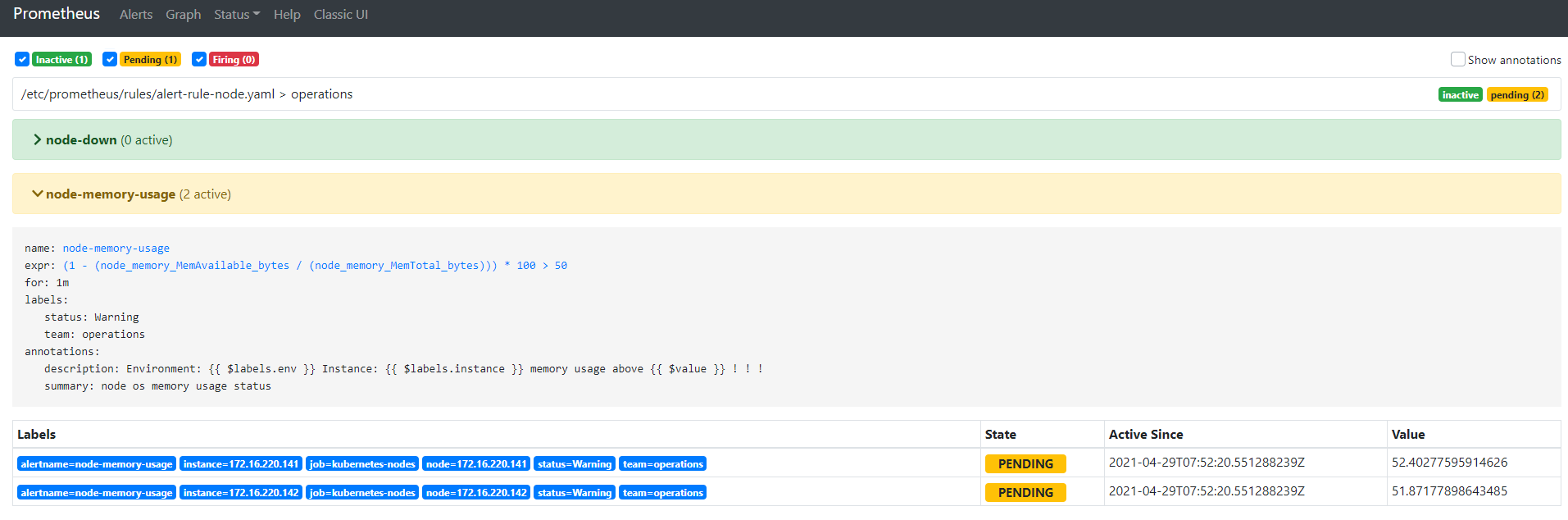
由于现在环境没有达到告警所需的值,我们可以调整判断值来触发告警。
expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes)))* 100 > 50
应用配置,等待一小会儿后即可看到告警状态转换:
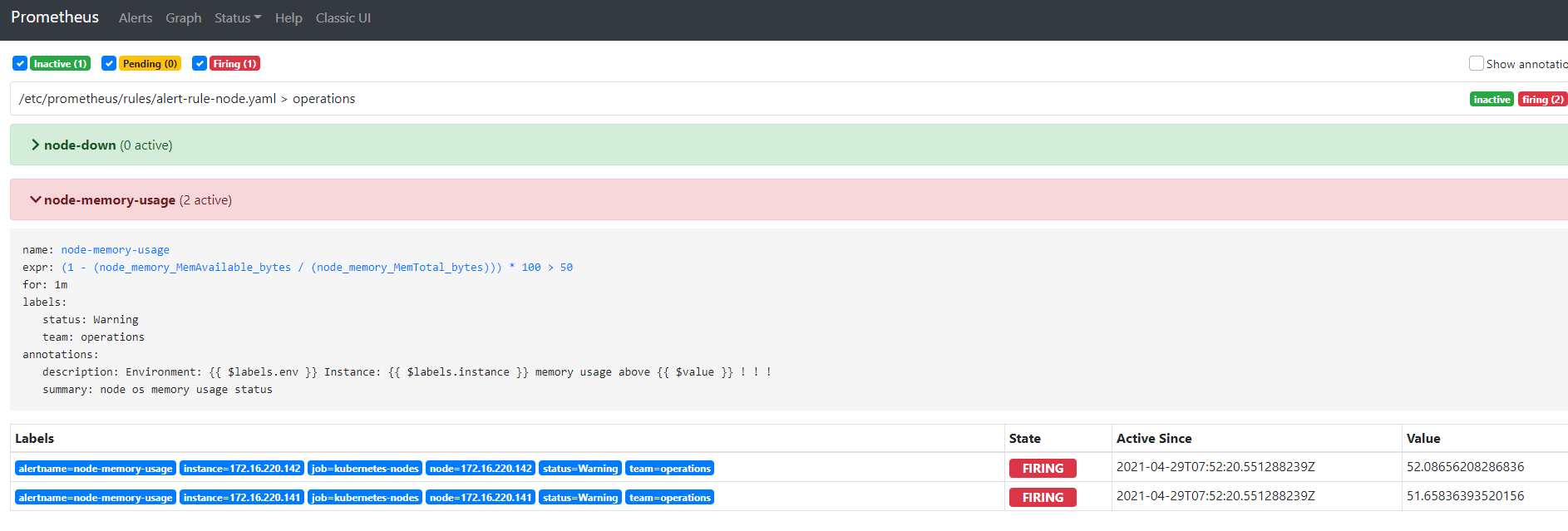
It is a pity, that now I can not express – it is very occupied. I will return – I will necessarily express the opinion on this question.