
概括
由于工作需要,每日需要统计数据库中表的条目数,然后将它们整合到一个Excel文档中。
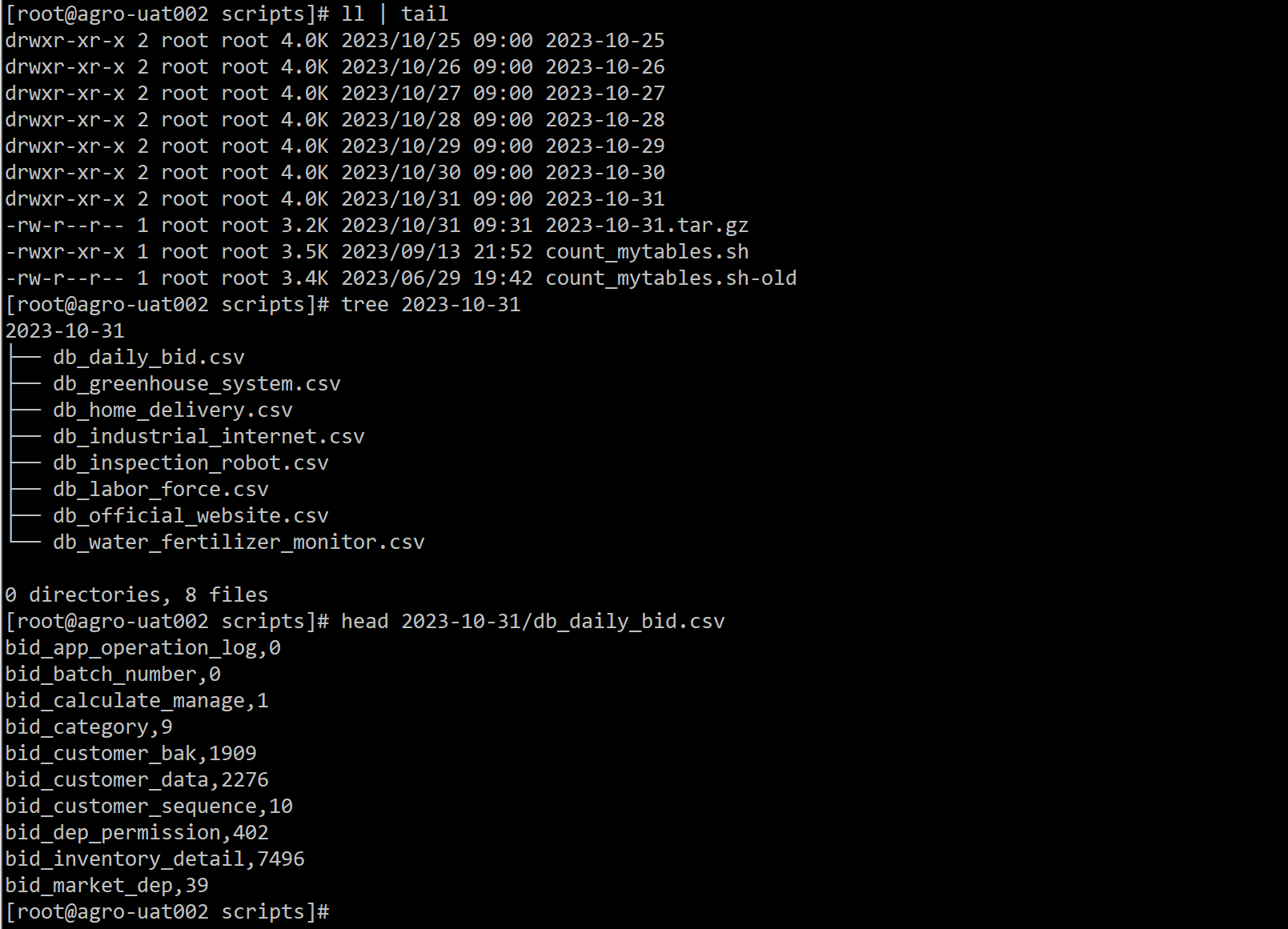
统计任务写了SHELL脚本每天定时执行,通过库信息连接对应的数据库,获取所有表和对应表数据的数量,将结果存储在以库名为文件名,以逗号分隔的 csv 文件中。如下:
整合的表如下,不同的库记录在不同的Sheet页面,Sheet页面内追加记录每天所收集到的信息:
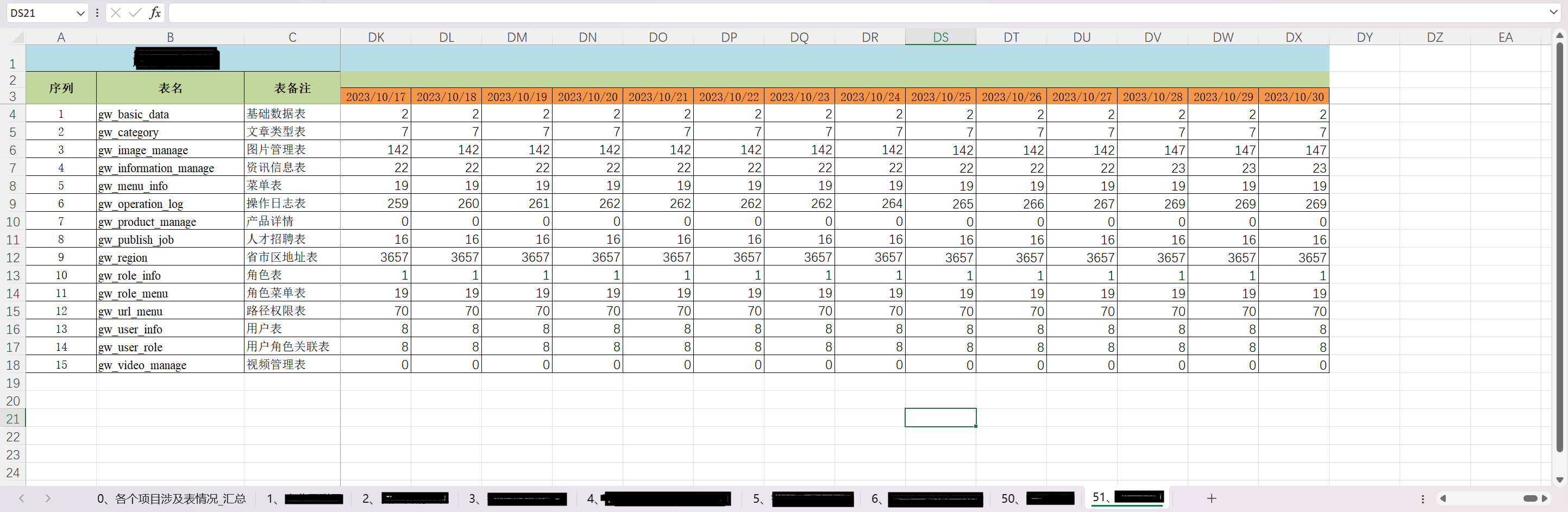
之前是手动添加日期复制追加处理,再加上调整格式,有时会占用不少时间。
改变
现创建了python脚本,通过输入既定格式日期,会将指定日期目录中的数据值复制/追加到表对应的Sheet页中。
from openpyxl import load_workbook
from datetime import datetime
from copy import copy
import pandas as pd
main_file = '项目数据表汇总整理'
print('本脚本用于将指定日期的库表统计信息操作表:',main_file,',并保存成新文件')
user_input = input("请输入日期(格式: 20121225): ")
date_input = datetime.strptime(user_input, '%Y%m%d').date()
date_instr = date_input.strftime('%Y-%m-%d')
today = datetime.now().date()
#print(type(today))
#print(type(today.strftime('%Y-%m-%d 00:00:00')))
# 主操作Excel文件
workbook = load_workbook(main_file+'.xlsx')
savebook = main_file+'_'+user_input+'_v5.2.xlsx'
# 表字典
sheet_dict = {
"1、AA互联网":"db_industrial_internet",
"2、BB系统":"db_daily_bid",
"3、CC机器人":"db_inspection_robot",
"4、DD一体机 (新)":"db_water_fertilizer_monitor",
"5、EE系统":"db_labor_force",
"6、FF系统":"db_greenhouse_system",
"50、GG商城":"db_home_delivery",
"51、HH官网":"db_official_website"
}
for ops_sheet,ops_excel in sheet_dict.items():
print('处理Sheet页:', ops_sheet)
# 选择要操作的Sheet页
sheet = workbook[ops_sheet]
row_number = 3
row_cells = sheet[row_number]
column_number = None
#print(today.strftime('%Y/%#m/%#d'))
for cell in row_cells:
#print(cell.value)
if isinstance(cell.value, str):
cell_date = datetime.strptime(cell.value, '%Y-%m-%d %H:%M:%S').date()
elif isinstance(cell.value, datetime):
cell_date = cell.value.date()
else:
continue
if cell_date == date_input:
column_number = cell.column
break
# 如果找到了列号,则输出;否则,在行末尾添加新列
if column_number:
print(f"找到列号:{column_number}")
else:
new_column = sheet.max_column + 1
new_cell = sheet.cell(row=row_number, column=new_column)
new_cell.value = date_input
# 复制之前列的格式
for num in range(1, row_number + 1):
previous_cell = sheet.cell(row=num, column=new_column - 1)
ncell = sheet.cell(row=num, column=new_column)
ncell.number_format = previous_cell.number_format
ncell.font = copy(previous_cell.font)
ncell.border = copy(previous_cell.border)
ncell.fill = copy(previous_cell.fill)
ncell.alignment = copy(previous_cell.alignment)
column_number = new_column
print(f"追加列号:{column_number}")
# 打开对应表,复制数据
print('打开对应csv表以复制数据:',date_instr+'/'+ops_excel+'.csv')
source_file = pd.read_csv(date_instr+'/'+ops_excel+'.csv', header=None)
# 获取第二列数据
column_data = source_file.iloc[:, 1]
# 操作文件的起始行
start_row = 4
for index, value in enumerate(column_data, start=start_row):
sheet.cell(row=index, column=column_number, value=value)
previous_cell = sheet.cell(row=index, column=column_number - 1)
sheet.cell(row=index, column=column_number).number_format = previous_cell.number_format
sheet.cell(row=index, column=column_number).border = copy(previous_cell.border)
print('已将数据复制至列:',column_number,'起始行:',start_row,'\n')
# 保存Excel文件
workbook.save(savebook)
print('文件已保存:',savebook)
# 关闭Excel文件
workbook.close()
这里我隐去了具体的库名称。
页码: 1 2