目前,LM Studio作为最受欢迎的本地LLM图形界面之一,在模型加载和格式兼容性上仍有进步空间。尤其是对新兴的MTP(Mixture of Experts Tensor Parallelism或其他多专家并行优化)格式支持尚不完善,近期下载了很多新模型使用,在尝试加载Gemma 4系列的MTP变体时就会遇到兼容性问题,MTP文件与模型在同一目录,程序中被标识为“gemma4-assisstant”,无法在主模型中选择使用,运行时也不会加载。经过了解,是官方底层还没更新支持,于是我查看并转向使用更底层的工具——llama.cpp。
Gemma 4作为Google最新一代开源大模型,以高效的推理能力和多模态潜力备受关注。其MTP优化版本在特定硬件上能显著提升吞吐量和内存效率。下面介绍如何使用llama.cpp(或其衍生工具如llama-server)运行支持MTP的Gemma 4模型,助力你实现本地高效部署。
为什么选择llama.cpp运行Gemma 4 MTP
-
更好的兼容性:llama.cpp持续跟进Hugging Face最新GGUF格式转换,支持更多实验性量化与并行技术。
-
性能优化:原生支持Tensor Parallelism、专家并行等,能更好地利用多GPU或高带宽内存。
- 灵活性高:可通过命令行或WebUI灵活配置,适合开发者和进阶用户。
- 社区活跃:GGUF转换脚本和预转换模型更新迅速。
准备工作
-
硬件要求:
-
GPU:推荐NVIDIA(CUDA)或AMD(ROCm/Vulkan),多卡并行更佳。
-
内存:Gemma 4 12B/26B/31B等规模模型,量化后需至少16-64GB VRAM/RAM(视上下文长度)
-
系统:Windows/Linux/macOS均可。
-
- 获取llama:
- 从网站下载编译好的二进制版本:https://github.com/ggml-org/llama.cpp/releases;
- 这里我下载的是当天最新版的 llama-b9860-bin-win-cuda-13.3-x64.zip 和 cudart-llama-bin-win-cuda-13.3-x64.zip,前一个是程序包,后一个是cuda链接库文件,当程序识别不到显卡时,下载其将内容文件放入程序目录中即可。
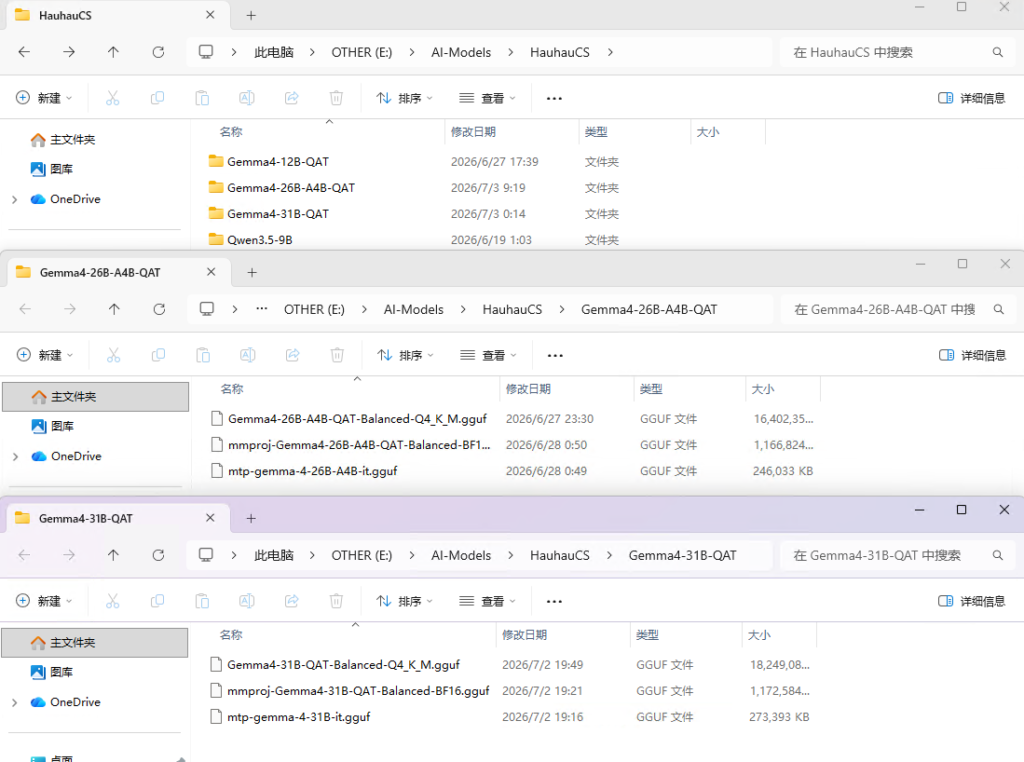
- 获取支持MTP的Gemma4模型:
-
在Hugging Face搜索Gemma-4相关仓库,寻找已转换为GGUF格式且标注支持MTP的版本(例如Gemma-4-12B-MTP-Q4_K_M.gguf等)。
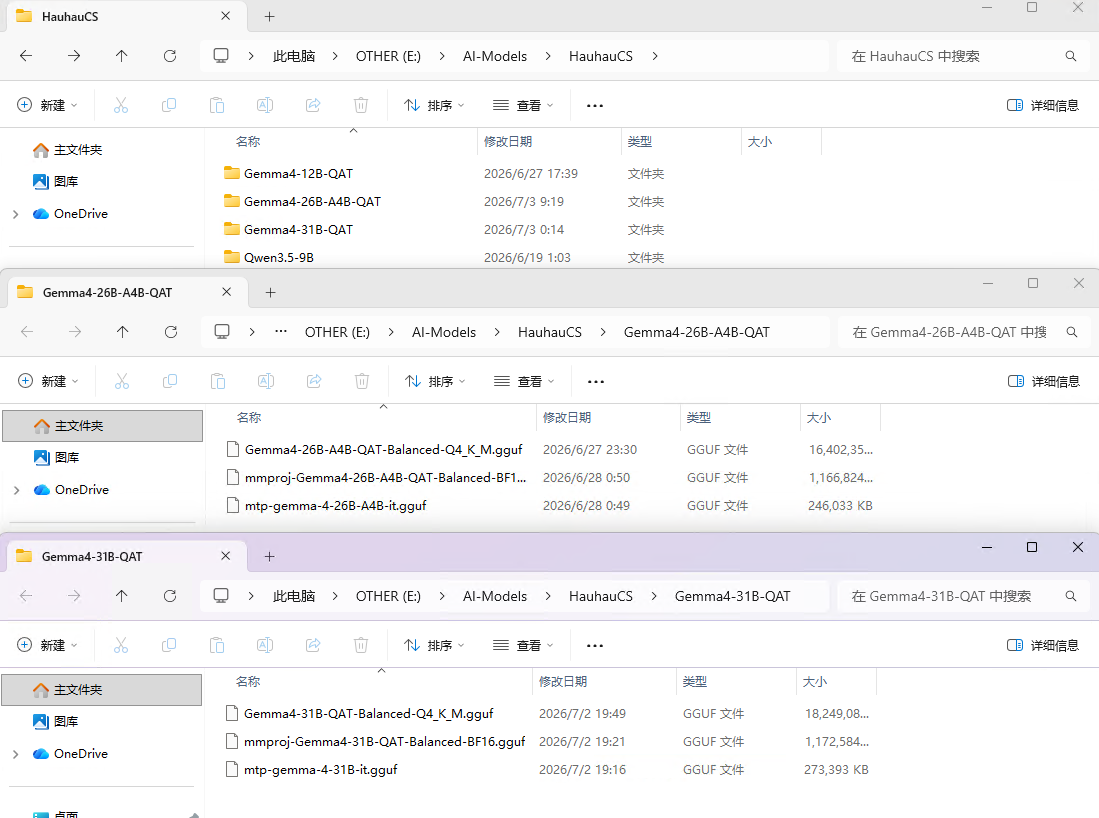
- 这里我使用的是HauhauCS的去审查版,将主模型,视频模型和MTP模型放入模型目录中。
-
安装部署
- 将程序llama-b9860-bin-win-cuda-13.3-x64.zip解压,为了后期更新替换方便,我将目录更名为了llama-bin-win-cuda-13。
- 将cudart-llama-bin-win-cuda-13.3-x64.zip中的三个文件cublas64_13.dll、cublasLt64_13.dll和cudart64_13.dll解压放入程序目录中。
- 这里我存放在“D:\PATH”路径下,与之后脚本中的路径相对应,你也可以更改为自己习惯的路径。
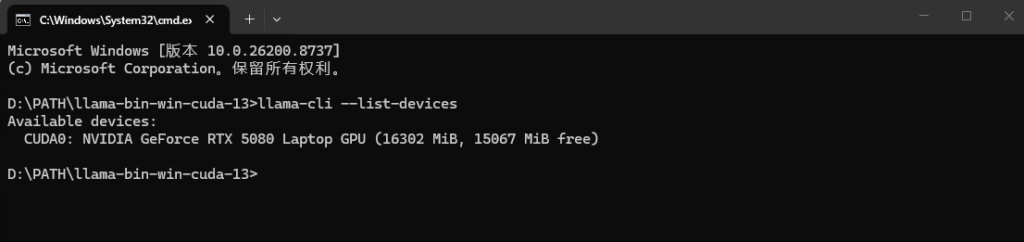
- 在路径下运行cmd,执行命令“llama-cli –list-devices”,检查有你发现你的显卡即可。
使用
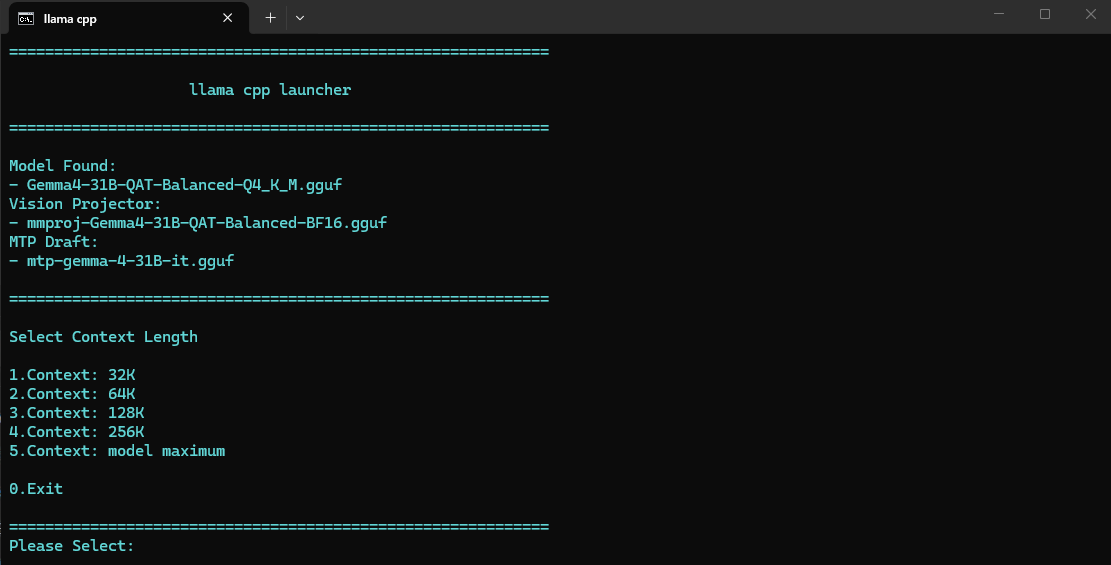
可直接使用命令行启动运行,这里我制作了BAT脚本,可直接启动运行,后续要切换模型直接更改其中model_path、gpu_layers变量中的模型目录和GPU层数即可。
脚本内容:
@Echo Off
Title llama cpp __Create by Chris@2026/07/03
Setlocal Enabledelayedexpansion
Color 0B
::Please Confirm the configure under line.
::<---------------------Configure Start.--------------------->
Set llama_path=D:\PATH\llama-bin-win-cuda-13
Set llama_port=8080
Set gpu_layers=32
Set model_path=E:\AI-Models\HauhauCS\Gemma4-31B-QAT
Set model=
Set mmproj=
Set mtp=
::<---------------------Configure End.----------------------->
If Not Exist %llama_path% (
Echo [Error]: llama path^(%llama_path%^) not exist, please check config.
Echo Windows will be colsed in 5 seconds.
Timeout /t 5 /nobreak > Nul
exit 1
) Else (Set "Path=%Path%;%llama_path%")
If Not Exist %model_path% (
Echo [Error]: model path^(%model_path%^) not exist, please check config.
Echo Windows will be colsed in 5 seconds.
Timeout /t 5 /nobreak > Nul
exit 1
) Else (cd /d %model_path%)
:: Search & defined LLM Models.
For %%i in (*.gguf) do (
set "filename=%%~ni"
if /i "!filename:~0,6!" == "mmproj" (
set "mmproj=%%i"
) else if /i "!filename:~0,3!" == "mtp" (
set "mtp=%%i"
) else (
set "model=%%i"
)
)
:Main
cls
Echo ============================================================
Echo.
Echo llama cpp launcher
Echo.
Echo ============================================================
Echo.
If defined model (
echo Model Found:
echo - !model!
) Else ( Echo [Error]: Model Not Found. )
If defined mmproj (
echo Vision Projector:
echo - !mmproj!
)
If defined mtp (
echo MTP Draft:
echo - !mtp!
)
Echo.
Echo ============================================================
Echo.
Echo Select Context Length
Echo.
Echo 1.Context: 32K
Echo 2.Context: 64K
Echo 3.Context: 128K
Echo 4.Context: 256K
Echo 5.Context: model maximum
Echo.
Echo 0.Exit
Echo.
Echo ============================================================
Set /p Num=Please Select:
If !Num! == 1 (
set ctx=32768
goto Exec
)
If !Num! == 2 (
set ctx=65536
goto Exec
)
If !Num! == 3 (
set ctx=131072
goto Exec
)
If !Num! == 4 (
set ctx=262144
goto Exec
)
If !Num! == 5 (
set ctx=0
goto Exec
)
If !Num! == 0 Exit
Goto Main
:Exec
cls
Echo ============================================================
Echo.
Echo Starting llama server...
Echo.
Echo Model:
Echo - !model!
Echo.
Echo Vision:
Echo - !mmproj!
Echo.
Echo MTP:
Echo - !mtp!
Echo.
Echo GPU Offload:
Echo - %gpu_layers%
Echo.
Echo Context:
Echo - %ctx%
Echo.
Echo OpenAI Compatible API:
Echo - http://127.0.0.1:%llama_port%/v1
Echo.
Echo ============================================================
Echo.
If Not defined model (
echo [Error]: No model found in %model_path%
pause > nul
goto Main
)
Set ext_args=
If defined mmproj (
set ext_args=--mmproj "!mmproj!"
)
If defined mtp (
set ext_args=!ext_args! -md "!mtp!" --spec-type draft-mtp
)
:: fit off 强制关闭有 Bug 的内存适配功能,交由手动指定的 -ngl 来接管显存。
llama-server.exe ^
-m "!model!" ^
!ext_args! ^
-ngl %gpu_layers% ^
-c %ctx% ^
-n 4096 ^
-fa on ^
--fit off ^
--host 127.0.0.1 ^
--port %llama_port%
Echo Operation is Done! & Pause > Nul
Goto Main
::<---------------------------------------------------------->
BAT脚本指定的绝对路径,没有目录存放要求,直接运行即可。
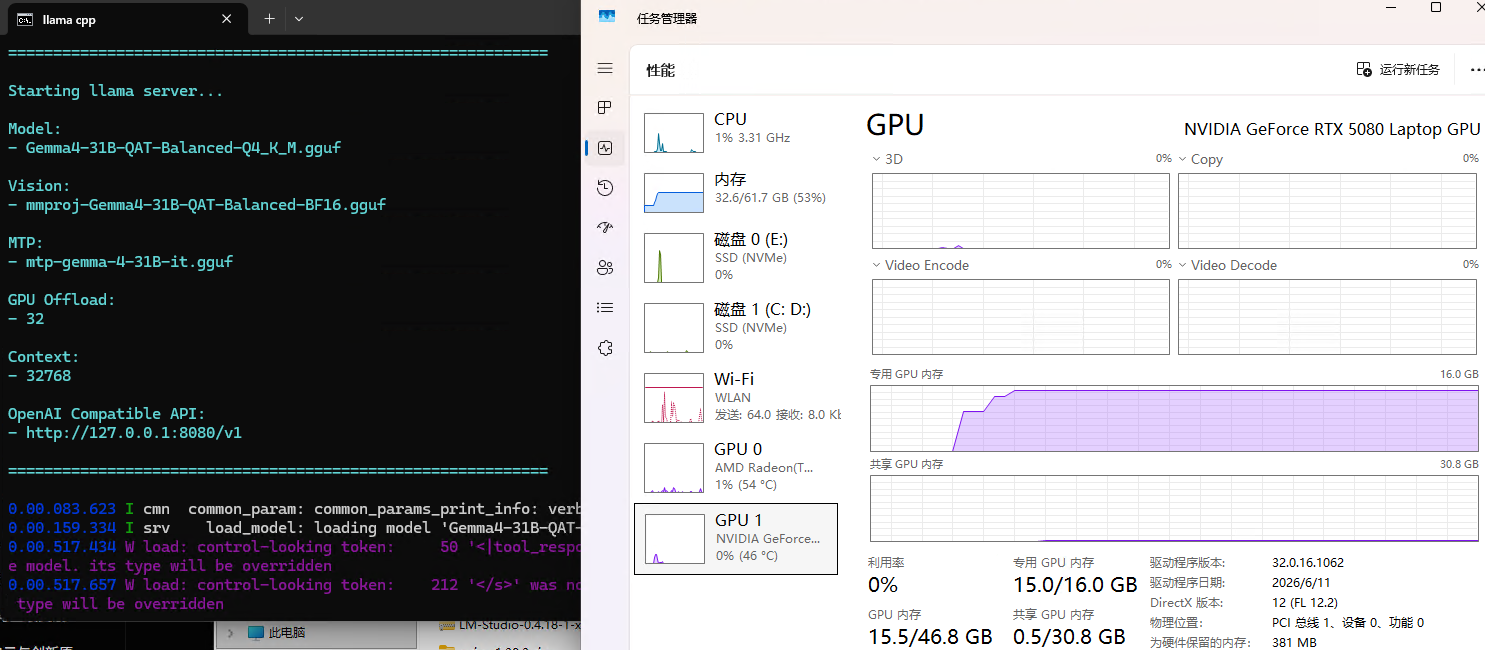
Tips:适量降低GPU Offload层数,可以增加上下文加载的长度。同样,如果提示内存不够启动失败,降低这两的值即可。
效果
显存16G的5080运行31B模型稍有吃力,虽然有MTP加持,Token数在8.91 t/s左右。

运行26B A4B的则快多了,有MTP,Token数可达45.26 t/s。